
AMD Ele publicou recentemente uma patente para distribuir a carga da tela em vários chips de GPU. O cenário do jogo é dividido em blocos individuais e distribuídos em tábuas de madeira para melhorar o uso do sombreamento nos jogos. Um recipiente de folha de dois níveis é usado para isso.
AMD publica patente para implementação de chiplets de GPU para melhor uso da tecnologia shader
Uma nova patente publicada pela AMD abre mais informações sobre o que a empresa planeja fazer com a tecnologia de GPU e CPU de próximo nível nos próximos anos. No final de junho, foi revelado que 54 pedidos de patentes haviam sido submetidos para publicação. Não se sabe qual das mais de cinquenta patentes publicadas será usada nos planos da AMD. As aplicações discutidas nas patentes ilustram a abordagem da empresa nos anos seguintes.
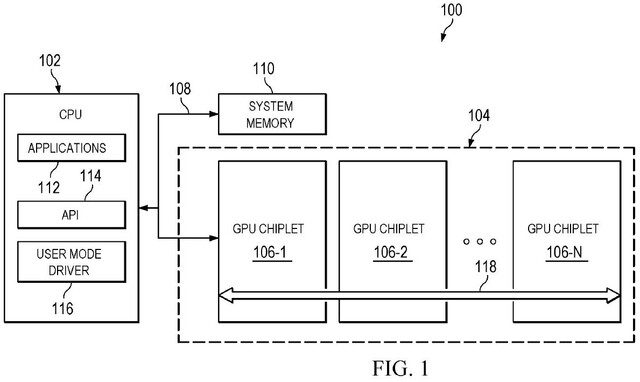
Um aplicativo que o membro da comunidade @ETI1120 notou no site base de computadornúmero da patente US20220207827, discute dados de imagem críticos em dois estágios para transmitir com eficiência cargas de exibição da GPU em vários chips. Esta CPU inicialmente aplicada ao Escritório de Patentes dos EUA no final do ano passado.
Quando os dados de imagem na GPU são rasterizados por meios padrão, a unidade de sombreamento, também conhecida como ALU, executa a tarefa semelhante e atribui um nome de cor aos pixels individuais. Em contraste, os polígonos texturizados encontrados no pixel selecionado em uma determinada cena do jogo são mapeados diretamente para o pixel. Por fim, a tarefa formulada manterá princípios atípicos e diferirá apenas por outras texturas localizadas em diferentes pixels. Este método é chamado SIMD, ou Instrução Única – Dados Múltiplos.

Para a maioria dos jogos atuais, os shaders não são a única tarefa que a GPU deu à luz. Mas, em vez disso, muitos elementos de pós-processamento são incluídos após o sombreamento inicial. As ações que a GPU adicionará, por exemplo, serão a prevenção de anti-aliasing, vinhetas e bloqueios no ambiente do jogo. No entanto, o ray tracing ocorre junto com o sombreamento, criando um novo método de computação.
Quando falamos sobre a GPU que controla os gráficos nos jogos atuais, a carga gerada por computador aumenta exponencialmente para milhares de unidades computacionais.
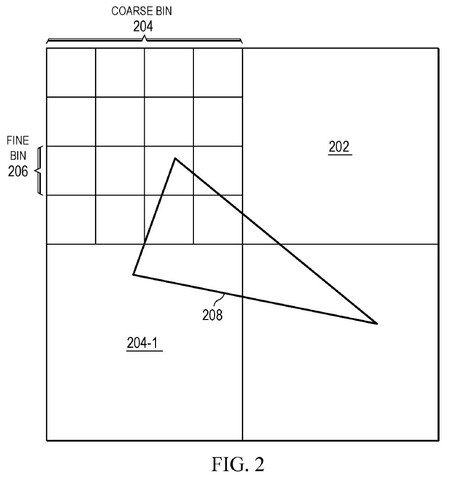
Em jogos em GPUs, essa carga de computação chega a vários milhares de unidades de computação de uma maneira bastante ideal. Isso difere dos processadores, pois os aplicativos precisam ser escritos especificamente para adicionar mais núcleos. O agendador de CPU cria essa ação e divide o trabalho da GPU em tarefas mais compreensíveis que são tratadas por unidades de computação, também chamadas de binning. A imagem do jogo é apresentada e depois dividida em blocos separados contendo uma quantidade especificada de pixels. O bloco é computado por uma subunidade de processador gráfico, onde é sincronizado e gerado. Após este procedimento, os pixels aguardando para serem contados são incluídos em um bloco até que a subunidade da placa gráfica seja finalmente utilizada. São feitas considerações para poder de computação de sombreamento, largura de banda de memória e tamanhos de cache.
A AMD afirma na patente que o particionamento e a junção exigem uma conexão de dados abrangente e completa entre todos os elementos da GPU, o que representa um problema. Os links de dados que não estão no modelo têm um alto nível de latência, o que torna o processo mais lento.
As CPUs fizeram essa transição para chiplets sem esforço devido à sua capacidade de enviar o trabalho por vários núcleos, tornando-os muito acessíveis aos chiplets. As GPUs não oferecem a mesma flexibilidade, o que as torna comparáveis a um pré-processador dual-core.
A AMD reconhece a necessidade e tenta fornecer respostas a esses problemas alterando o pipeline de rasterização e enviando tarefas entre várias GPUs, semelhantes às CPUs. Isso requer tecnologia avançada de binning, que a empresa oferece “binning binning”, também conhecida como “binning binning”.


Na supermontagem, a divisão é processada em duas fases separadas, em vez de processamento direto em blocos pixel a pixel. O primeiro passo é calcular a equação, pegar um ambiente 3D e criar uma imagem 2D a partir do original. O estágio é chamado de vertex shaders e é concluído antes da rasterização, e o processo é muito pequeno no primeiro chip da GPU. Uma vez terminado, a cena do jogo começa a desaparecer, evoluindo para caixas irregulares e processando em um único chip GPU. Depois disso, as tarefas de rotina, como pontilhar e pós-processamento, podem começar.


Não se sabe quando a AMD pretende começar a usar esse novo processo ou se será aprovado. No entanto, isso nos dá um vislumbre do futuro do processamento de GPU mais eficiente.
fontes de notícias: base de computadorE a Patentes online grátis

“Viciado em zumbis amigo dos hipsters. Aspirante a solucionador de problemas. Entusiasta de viagens incuráveis. Aficionado por mídia social. Introvertido.”




More Stories
Uma empresa afirma que Barbie pode superar o vício em smartphones
Os jogadores reclamam do longo tempo de matchmaking no PS5 conforme os números do Concord caem
O próximo mini drone 4K da DJI cabe na palma da sua mão